



Alta probabilidade
“No cenário digital atual, que evolui rapidamente, as organizações precisam aproveitar estrategicamente tecnologias inovadoras...”
Avalia qualquer texto quanto à geração por IA: GPT-4, Claude, Gemini, Llama e mais.
No cenário digital atual, que evolui rapidamente, as organizações precisam aproveitar estrategicamente tecnologias inovadoras para otimizar a eficiência operacional e desbloquear sinergias sem precedentes entre equipes multifuncionais.
“No cenário digital atual, que evolui rapidamente, as organizações precisam aproveitar estrategicamente tecnologias inovadoras...”
“...para otimizar a eficiência operacional e desbloquear sinergias sem precedentes entre equipes multifuncionais.”
curl https://api.walterwrites.ai/v1/detect
-H "Authorization: Bearer YOUR_API_KEY"
-H "Content-Type: application/json"
-d '{
"text": "In today's rapidly evolving digital landscape, organizations must strategically leverage innovative technologies to optimize operational efficiency and unlock unprecedented synergies across cross-functional teams.",
"language": "en""id": "det_4k2p9x1m3",
"status": "completed",
"model": "detector-v3",
"created_at": "2026-04-24T13:45:00Z",
"output": {
"ai_probability": "0.87’’
"words_processed": 12
"usage": { "credits_used": 12 }Benchmarks públicos, metodologia transparente, sem números escolhidos a dedo. Refaz os testes tu mesmo. Publicamos a metodologia.
| CAPACIDADE |
 Walter Writes
Walter Writes
| GPTZero | Originality.ai | Copyleaks | ZeroGPT |
|---|---|---|---|---|---|
| benchmark AFIP | 0.961 | 0.881 | 0.892 | 0.874 | 0.846 |
| Suporte entre idiomas | 31 | 9 | 7 | 27 | 8 |
| Destaques no nível da frase | Limitado | ||||
| Confiança calibrada | Parcial | ||||
| Benchmark público | Parcial | Parcial | |||
| Treina com o seu texto | Opt-out | Opt-out | Pouco claro | ||
| Benchmark AFIP |
Confiança calibrada, granularidade no nível da frase e latência mediana de 240 ms. Feito para produção, não só para demos.
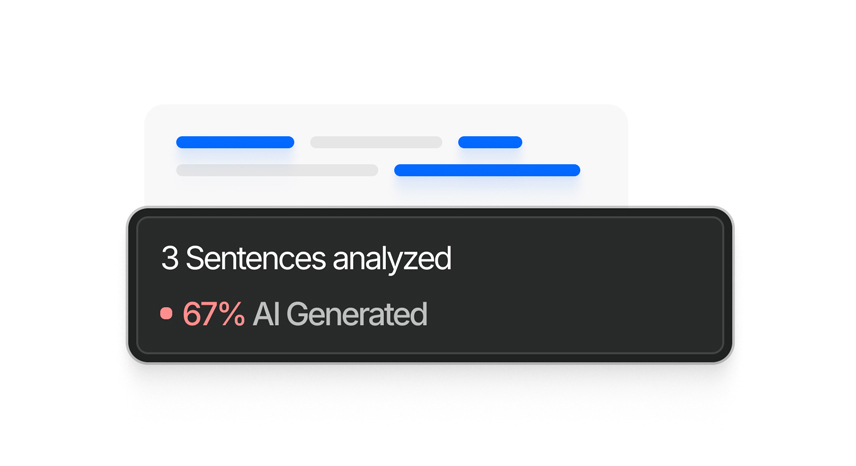
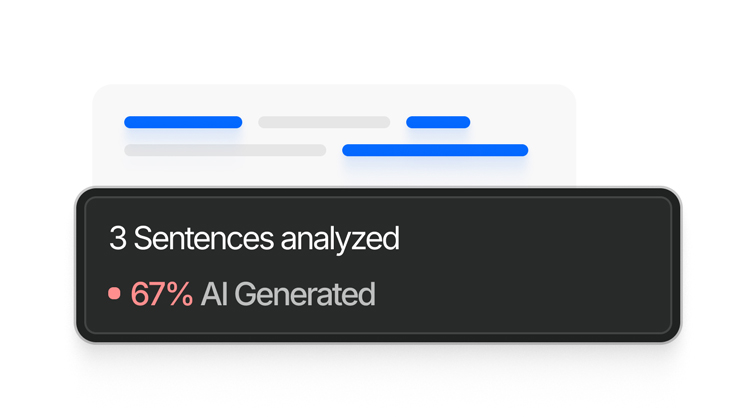
Pontua cada frase individualmente. Vê exatamente quais partes parecem geradas por IA, quais parecem humanas e quais ficam na zona mista.
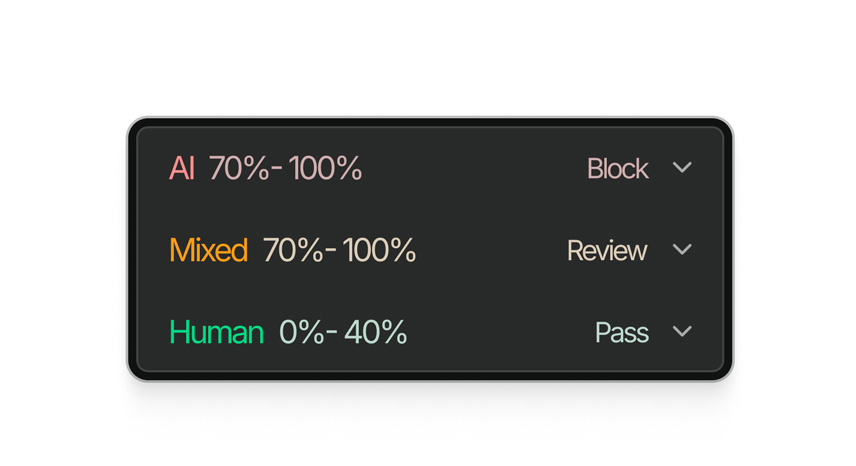
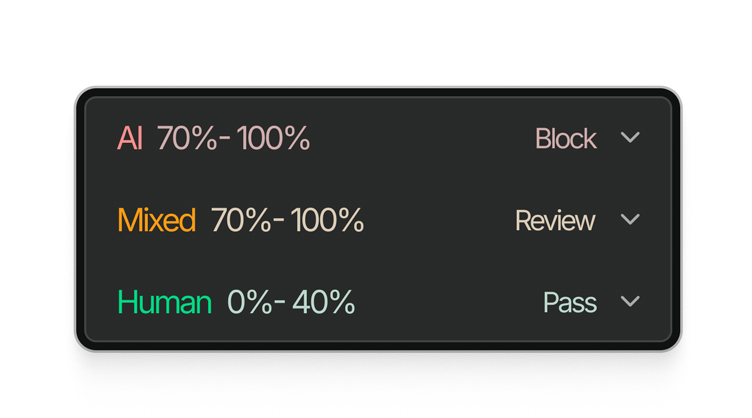
Cada resultado devolve um valor calibrado entre 0 e 1. Decide o que é sinalizado, revisado ou bloqueado, nos seus próprios termos.
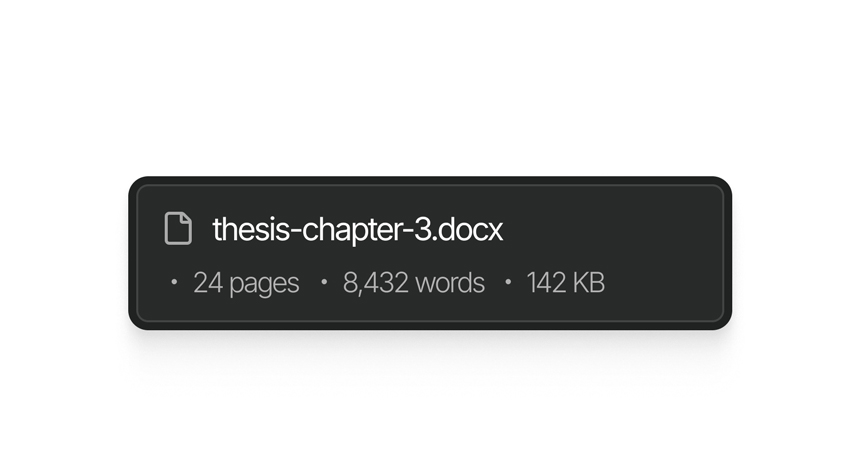
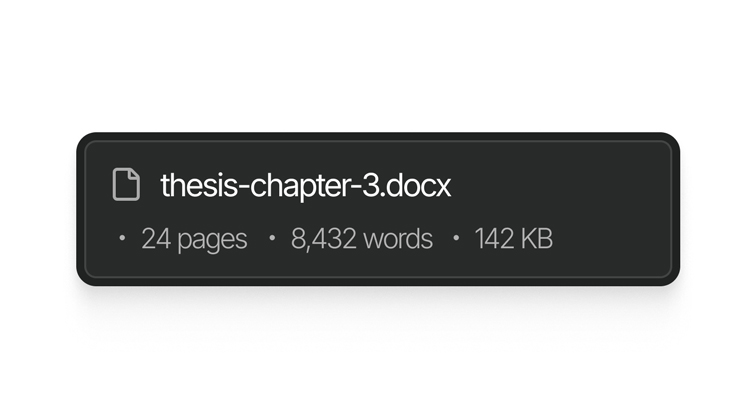
Processa redações completas, artigos ou transcrições numa única chamada. Sem lógica de divisão do seu lado, sem resultados remendados.
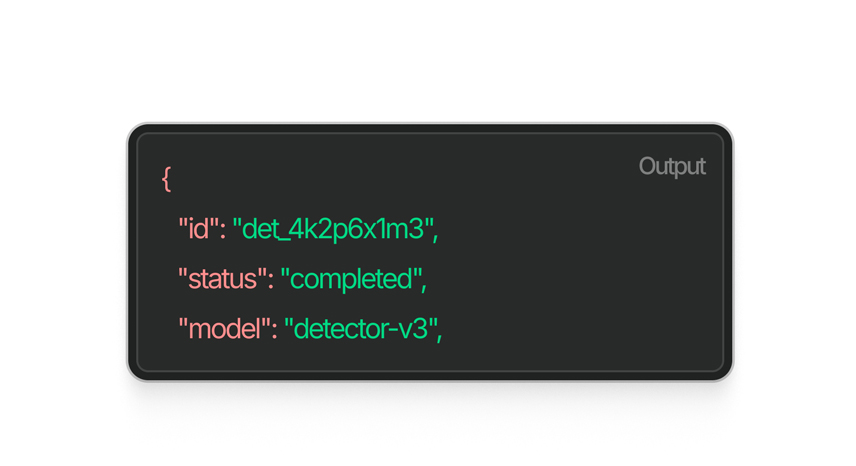

A mesma estrutura JSON em todas as chamadas. Sem campos condicionais, sem surpresas em produção, sem casos extremos para resolver depois.


Detecta texto gerado por IA em 31 idiomas sem trocar endpoints nem passar parâmetros extras.

Respostas em menos de um segundo no tráfego de produção. Faz a detecção inline no seu produto, não como tarefa em segundo plano.

De salas de aula a marketplaces de conteúdo e plataformas de recrutamento, uma detecção que se encaixa no fluxo de trabalho que a sua equipe já usa.
Integra no Canvas, Moodle, Schoology ou no seu próprio LMS para pontuar cada envio no upload. Painéis por aluno, tratamento de dados alinhado à FERPA e um plano Education com volume com desconto.
Sinaliza envios gerados por IA no momento da ingestão.
Pontua cartas de apresentação, tarefas para fazer em casa e respostas escritas de entrevistas.

A detecção fica mais poderosa quando combinada com humanização, plágio, gramática, imagem e voz. Tudo com uma única chave de API.

Usa o Walter dentro do Claude. Plugin MCP para fluxos de trabalho nativos de IA.


Reescreve texto gerado por IA em uma saída natural, com cara de humana, que passa pela detecção.
Detecta voz gerada por IA e voz clonada em áudio com pontuação de confiança no nível do locutor.


Compara o texto com bilhões de fontes da web e bases acadêmicas para encontrar correspondências de originalidade.

Encontra problemas de gramática, ortografia e estilo com sugestões contextuais no nível da frase.


Detecta imagens geradas por IA e manipuladas nos principais modelos.
Planos mensais com cotas de palavras incluídas. Sem compromisso. Descontos por volume já incluídos.
Precisas de preços enterprise?
Capacidade dedicada, fixação por região e modo de retenção zero para equipes de alto volume.
Respostas com base em pesquisa sobre precisão da detecção, viés e casos extremos.
A precisão dos detectores de IA em 2026 varia muito conforme o fornecedor. Os melhores detectores, como Walter e Originality, atingem AUC 0,9+ (área sob a curva) em conjuntos de dados de benchmark, enquanto alguns detectores comerciais mal se saem melhor do que um palpite aleatório. Segundo o estudo do benchmark RAID (arxiv.org/abs/2405.07940), o Walter marca 0,961 de AUC em dados de testes padronizados. No entanto, a precisão no mundo real depende bastante de vários fatores: tipo de texto (artigos acadêmicos vs. posts casuais de blog vs. documentação técnica), tamanho do documento (textos curtos são mais difíceis de classificar com precisão) e idioma (modelos treinados em inglês têm dificuldade com outros idiomas). Escrita acadêmica com estrutura formal tende a ser mais fácil para os detectores analisarem do que conteúdo conversacional. Ao avaliar qualquer detector de IA, pede métricas de desempenho em textos parecidos com os teus, e não apenas alegações de precisão geral. A diferença entre detectores de ponta e os mais fracos é grande, então escolher uma solução bem avaliada em benchmarks faz diferença se a precisão for crítica para o seu caso de uso.
Sim, detectores de IA mostram um viés significativo contra falantes não nativos de inglês. Uma pesquisa de Liang et al. (2023), publicada na Patterns, descobriu que detectores populares como GPTZero e ZeroGPT classificaram incorretamente até 61% de redações do TOEFL escritas por não nativos como geradas por IA (https://arxiv.org/abs/2304.02819). Isso acontece porque essas ferramentas confundem estruturas de frase mais simples e vocabulário limitado, comuns na escrita de ESL, com padrões de IA. O Walter enfrenta esse problema diretamente ao treinar com corpora diversos de escrita ESL para reduzir falsos positivos em não nativos. Também reportamos separadamente as taxas de falso positivo em ESL no nosso benchmark público, dando-te uma transparência que outros fornecedores não oferecem. Se o seu caso de uso envolve usuários internacionais, estudantes ou equipes globais, entender esse viés é essencial. A API do detector de IA do Walter oferece resultados mais justos em diferentes níveis de proficiência em inglês, sendo uma escolha melhor para instituições educacionais e plataformas que atendem populações diversas.
Sim, detectores de IA podem errar, e falham de duas formas principais. Falsos positivos acontecem quando um texto escrito por humano é sinalizado como gerado por IA, enquanto falsos negativos acontecem quando conteúdo gerado por IA passa sem ser detectado. A maioria dos detectores apresenta taxas de falso positivo entre 4,12% quando configurados para um limiar de confiança de 50%, ou seja, escrita humana legítima é sinalizada incorretamente aproximadamente uma vez a cada 10,25 amostras. O problema de precisão piora com certos estilos de escrita, com falantes não nativos de inglês e com conteúdo altamente técnico. A API do detector de IA do Walter resolve isso ao fornecer pontuações de confiança calibradas, em vez de respostas binárias de sim/não. Assim, tu escolhes o seu próprio limiar com base no seu caso de uso. Se falsos positivos custam caro, podes exigir maior confiança antes de sinalizar conteúdo. Se capturar conteúdo de IA é crítico, podes baixar o limiar e aceitar mais alarmes falsos. A tecnologia de detecção continua melhorando, mas quem promete 100% de precisão está exagerando. A realidade é que a detecção de IA é probabilística, não definitiva.
Falsos positivos na detecção de IA acontecem quando a escrita humana aciona algoritmos de correspondência de padrões treinados principalmente com amostras de inglês nativo. As causas mais comuns incluem escrita de não nativos (autores de ESL costumam ter menor diversidade lexical, o que se parece com saída de IA), escrita muito formal ou técnica que segue modelos rígidos e textos com menos de 100 palavras, em que padrões estatísticos ficam pouco confiáveis. Conteúdo humano excessivamente editado também perde variação natural, fazendo parecer gerado por máquina. Resumos acadêmicos são especialmente propensos a sinalizações indevidas porque sua estrutura padronizada imita dados de treinamento de IA. A API do humanizador de IA do Walter lida com isso por meio de técnicas de redução de viés que preservam o seu significado pretendido enquanto adicionam variação linguística natural. Nossa abordagem ajusta perplexidade e burstiness sem comprometer a clareza, ajudando conteúdo escrito por humanos a passar por ferramentas de detecção, mantendo qualidade profissional. Especialmente para conteúdo técnico ou de ESL, isso significa menos sinalizações injustas e mais confiança ao publicar.
Fornecemos pontuações de probabilidade calibradas (0,1) em vez de vereditos binários de sim/não, para que a sua equipe de produção possa definir limiares que combinem com a sua tolerância a risco. Cada resposta da API inclui intervalos de confiança e detalhamentos no nível da frase que destacam exatamente onde o modelo está incerto. Assim, revisores humanos podem focar em trechos ambíguos em vez de reler documentos inteiros. Para casos de alto impacto, como integridade acadêmica ou triagem de RH, recomendamos implementar um fluxo de revisão em duas etapas: sinalizar conteúdo acima do limiar escolhido e, em seguida, pedir que especialistas do domínio examinem as frases sinalizadas usando nosso detalhamento. Essa abordagem reduz drasticamente o impacto de falsos positivos, mantendo o tempo de revisão sob controle. Tu controlas o nível de sensibilidade, e nós entregamos os dados granulares para tomar decisões bem informadas sobre casos extremos.
Sim, a API do detector de IA continua eficaz graças ao retreinamento contínuo. O Walter atualiza os modelos de detecção mensalmente usando saídas dos LLMs mais recentes, incluindo GPT-5, Claude 4 e Gemini 2.5 conforme são lançados. Embora pesquisas como “Can AI-Generated Text be Reliably Detected?” (Sadasivan et al., 2023, arxiv.org/abs/2303.11156) mostrem que, no longo prazo, burlar a detecção é teoricamente ilimitado, na prática a precisão se mantém alta quando os detectores acompanham a evolução dos modelos. O segredo é manter-se atualizado com novos padrões de lançamento e dados de treinamento. O Walter publica uma linha do tempo de precisão com métricas de desempenho em diferentes gerações de modelos, para que tu vejas exatamente como a detecção se sustenta conforme os LLMs avançam. Enquanto o detector for retreinado regularmente com saídas recentes de modelos, em vez de depender de dados estáticos, ele continua identificando conteúdo gerado por IA de forma confiável. Pensa nisso como um antivírus: a eficácia depende de atualizações regulares para reconhecer novas ameaças.