










Wie gut erkennen KI-Detektoren eigentlich deutsche Texte? Diese Frage hört man an Hochschulen, in Redaktionen und in Lehrerzimmern immer öfter. Eine belastbare Antwort gab es bisher kaum, denn fast alle veröffentlichten Tests arbeiten mit englischen Texten. Wir haben das geändert.
Für diesen Benchmark haben wir 60 deutsche Texte durch 3 KI-Detektoren mit programmatischem Zugang geschickt: den Walter Writes KI-Detektor, GPTZero und ZeroGPT. Ein Drittel der Texte stammt nachweislich von Menschen, ein Drittel wurde von einem aktuellen Sprachmodell erzeugt, ein Drittel wurde nach der KI-Generierung mit einem Überarbeitungs-Tool in zwei Durchläufen umgeschrieben. Jeder Detektor musste jeden Text bewerten, unter identischen Bedingungen: 180 Einzelmessungen, alle am 12. Juni 2026.
Eine Sache vorweg, weil sie für die Einordnung wichtig ist: Walter Writes ist unser eigenes Produkt. Wir haben den Test deshalb so aufgebaut, dass alle drei Tools exakt gleich behandelt werden, die Bewertungsregeln vor dem Testlauf fixiert waren und sämtliche Rohdaten zum Nachprüfen bereitstehen. Wo ein Ergebnis unbequem ist, steht es trotzdem in der Tabelle.
Das Wichtigste in Kürze: Unser Benchmark mit 60 deutschen Texten (Juni 2026) hat zwei Ebenen. Im Kern-Benchmark aus 20 menschlichen und 20 unveränderten KI-Texten erreichte der Walter Writes KI-Detektor 40 von 40 korrekte Signale (GPTZero: 39 von 40, ZeroGPT: 22 von 40). Besonders wichtig: Walter Writes und GPTZero markierten keinen einzigen menschlichen Text fälschlich mit einem hohen KI-Signal.
Im bewusst schwierigen Stress-Test mit 20 zweifach überarbeiteten KI-Texten wurde die Erkennung bei allen drei Tools unsicher. Rechnet man diesen Stress-Test ein, zeigte Walter in diesem Testfeld das stärkste Gesamtprofil: 47 von 60 passende Signale, null False Positives und 20 von 20 hohe Signale bei unveränderten KI-Texten. Wichtigste Lektion: Ein Detektor-Score ist ein KI-Ähnlichkeits-Signal, kein Beweis. Der sicherste Arbeitsablauf kombiniert Erkennung, Überarbeitung, menschliche Prüfung und eine abschließende Kontrolle.
Die Kernergebnisse auf einen Blick
- Kern-Benchmark (menschliche + unveränderte KI-Texte): Der Walter Writes KI-Detektor erreichte 40 von 40 korrekten Signalen, GPTZero 39 von 40, ZeroGPT 22 von 40.
- False Positives: Walter Writes und GPTZero markierten 0 von 20 menschlich geschriebenen deutschen Texten fälschlich als KI. ZeroGPT markierte 7 von 20, darunter Lexikonartikel über Marie Curie (96,6 Prozent KI-Signal) und die Nordsee (90,7 Prozent), die nachweislich vor 2020 geschrieben wurden.
- Stress-Test mit überarbeiteten KI-Texten: Von 20 KI-Texten, die zwei Walter-Überarbeitungsdurchläufe durchlaufen hatten, bekamen im Schnitt nur noch knapp 4 pro Tool ein hohes KI-Signal (Walter Writes: 7, GPTZero: 3, ZeroGPT: 1). 12 der 20 Texte erhielten bei allen drei Tools ein niedriges Signal. Genau deshalb gehört nach jeder Überarbeitung eine menschliche Prüfung in den Arbeitsablauf.
- Gesamtübereinstimmung inklusive Stress-Test: Walter Writes 47 von 60 Texten (78,3 Prozent), GPTZero 42 von 60 (70,0 Prozent), ZeroGPT 23 von 60 (38,3 Prozent).
Alle Zahlen in diesem Artikel stammen aus einem einzigen, dokumentierten Testlauf am 12. Juni 2026. Die vollständigen Rohdaten kannst du am Ende des Artikels herunterladen.
Warum dieser Test nötig war
KI-Detektoren werden überwiegend auf englischen Texten trainiert und auf englischen Texten getestet. Die großen Benchmark-Studien, die Anbieter gern zitieren, arbeiten fast ausschließlich mit englischsprachigem Material. Für den deutschen Sprachraum heißt das: Die beworbenen Genauigkeitswerte sind erst einmal nur eine Behauptung.
Deutsch unterscheidet sich strukturell deutlich vom Englischen. Längere Komposita, flexiblere Satzstellung, andere Satzlängenverteilungen, eine andere Häufigkeit von Funktionswörtern. Detektoren, die statistische Muster aus englischen Trainingsdaten gelernt haben, treffen bei deutschen Texten auf eine Verteilung, die sie so nicht kennen. Ob das die Signale verschlechtert, und falls ja, wie stark, lässt sich nur empirisch klären.
Gleichzeitig steigt das, was auf dem Spiel steht. An deutschen Hochschulen werden Detektor-Scores inzwischen in Plagiatsverdachtsfällen herangezogen. Schülerinnen und Schüler bekommen Arbeiten zurück, weil ein Tool 80 Prozent KI-Wahrscheinlichkeit angezeigt hat. Wer als nicht-muttersprachliche Person auf Deutsch schreibt, oft in gleichmäßigerem, vorsichtigerem Stil, trägt ein bekannt erhöhtes Risiko, fälschlich markiert zu werden. Ein False Positive ist hier kein statistisches Detail. Er kann eine Prüfungsleistung, ein Semester oder einen Ruf kosten.
Deshalb dieser Test: keine Marketingzahlen, sondern ein nachvollziehbarer Versuchsaufbau mit deutschen Texten, dokumentierten Metriken und herunterladbaren Rohdaten.
Methodik
Die Methodik ist das Herzstück dieser Studie. Sie wird hier vollständig beschrieben, damit jede und jeder den Test reproduzieren oder kritisieren kann.
Das Textkorpus: 60 deutsche Texte in drei Gruppen
Gruppe 1: 20 von Menschen geschriebene Texte. Für diese Gruppe brauchten wir Texte, deren menschliche Urheberschaft zweifelsfrei feststeht. Wir haben uns für Auszüge aus der deutschsprachigen Wikipedia (15 Texte) und aus Wikivoyage (5 Texte) entschieden, jeweils im Bearbeitungsstand von Dezember 2019, also Jahre vor der breiten Verfügbarkeit generativer Text-KI. Jede Revisions-ID ist dokumentiert und öffentlich nachprüfbar. Die Themen reichen von Honigbienen über Marie Curie bis zu Reiseinformationen über Berlin, das Register vom formellen Lexikonartikel bis zum lockeren Reiseführer-Ton, die Längen von 333 bis 479 Wörtern. Eine bewusste Grenze dieses Ansatzes: Studentische Essays oder private Blogposts mit gesicherter Vor-KI-Herkunft standen uns nicht zur Verfügung; das Korpus deckt also vor allem sachliche Register ab.
Gruppe 2: 20 KI-generierte Texte. Alle Texte dieser Gruppe wurden im Juni 2026 von einem aktuellen großen Sprachmodell auf Deutsch erzeugt (nicht wortwörtlich ChatGPT; die Muster moderner Sprachmodelle sind sich beim Fließtext sehr ähnlich). Um realistische Bedingungen abzubilden, kam nicht ein einziger Standardprompt zum Einsatz, sondern vier Prompt-Typen: einfache Schreibaufträge (7 Texte), Prompts mit Stilvorgaben wie journalistisch, akademisch oder Blog (7), Prompts mit der expliziten Anweisung, locker und menschlich zu klingen (4), sowie mehrstufige Prompts mit Überarbeitungsschleife (2). Themen und Längen wurden an Gruppe 1 angelehnt, damit die Gruppen vergleichbar bleiben. Die vollständige Promptliste liegt dem Datenpaket bei.
Gruppe 3: 20 überarbeitete KI-Texte. Die 20 Texte aus Gruppe 2 wurden anschließend in zwei Durchläufen mit dem Walter Humanizer überarbeitet (Modus „balanced“, Standardeinstellungen). Diese Gruppe bildet das Szenario ab, vor dem sich Prüfende am meisten fürchten: maschinell erzeugte Texte, die danach maschinell umgeschrieben wurden. Sie zeigt, wo die praktische Grenze der Detektion liegt. Auch hier volle Transparenz, weil es unser eigenes Tool ist: Der zweite Durchlauf veränderte in einem Text eine Mengenangabe und erzeugte stellenweise veraltete Schreibweisen. Maschinelle Überarbeitung ersetzt keine menschliche Schlussredaktion, und genau so steht es auch in unseren eigenen Empfehlungen weiter unten.
Die drei getesteten Detektoren
- Walter Writes KI-Detektor (API)
- GPTZero (API, mehrsprachiger Modus)
- ZeroGPT (öffentliche Web-Schnittstelle)
Getestet wurden bewusst nur Tools mit programmatischem Zugang. Nur so lassen sich 180 Messungen unter identischen, reproduzierbaren Bedingungen durchführen, ohne Browser-Sitzungen, Tageszeit-Effekte oder manuelle Übertragungsfehler. Bekannte Web-Tools ohne offene Schnittstelle (etwa der Scribbr KI-Detector, der Quillbot AI Detector oder die Copyleaks-Weboberfläche) fehlen deshalb in dieser Runde; eine Folgerunde mit browserbasierter Messung ist geplant. Es wurden keine Sondereinstellungen genutzt, die normalen Nutzerinnen und Nutzern nicht zur Verfügung stehen.
Testablauf
Jeder der 60 Texte wurde unverändert an jeden der drei Detektoren übergeben, insgesamt also 180 Einzelmessungen, alle am 12. Juni 2026. Für jede Messung wurden der ausgegebene Score, der Zeitstempel und die rohe API-Antwort gespeichert. Texte wurden nicht gekürzt, formatiert oder anderweitig angepasst.
Da die Tools unterschiedliche Ausgabeformate haben, wurde jede Ausgabe nach einem vorab festgelegten Schema in eine von zwei Klassen übersetzt: Ein KI-Ähnlichkeits-Score von 50 oder mehr (auf einer Skala von 0 bis 100) gilt als „hohes KI-Signal“, alles darunter als „niedriges KI-Signal“. Wichtig: Diese Regel wurde vor dem Testlauf fixiert, nicht nachträglich an die Ergebnisse angepasst. Ein einziger Grenzfall trat auf: Ein überarbeiteter Text erhielt von GPTZero einen Score von 49,96 Prozent und zählt nach der fixierten Regel als niedriges Signal, obwohl GPTZeros eigene Klassenbezeichnung „ai“ lautete. Auch das steht so in den Rohdaten.
Metriken
Fünf Kennzahlen wurden pro Detektor berechnet, getrennt nach Kern-Benchmark und Stress-Test:
- Kern-Benchmark: korrekte Signale über die 40 Texte mit klar definierter Aufgabe, also die 20 menschlichen Texte (korrekt = niedriges KI-Signal) und die 20 unveränderten KI-Texte (korrekt = hohes KI-Signal).
- False-Positive-Rate: Anteil der 20 menschlichen Texte mit hohem KI-Signal. Das ist die für Studierende und Lehrkräfte kritischste Zahl.
- False-Negative-Rate: Anteil der 20 unveränderten KI-Texte mit niedrigem KI-Signal.
- Stress-Test-Signalrate: Anteil der 20 zweifach überarbeiteten KI-Texte, die trotz Überarbeitung ein hohes KI-Signal bekamen. Dieser Teil ist bewusst die schwierigste Disziplin und wird separat ausgewiesen, weil überarbeitete Texte eine andere Erkennungsaufgabe sind als unveränderte KI-Texte.
- Gesamtübereinstimmung inklusive Stress-Test: Anteil aller 60 Texte, bei denen das Signal zur bekannten Herkunft passt. Diese Zahl ist keine allgemeine Produktgenauigkeit, sondern die Gesamtwertung über das bewusst anspruchsvolle Testfeld.
Grenzen des Tests
Auch eine sorgfältige Methodik hat Grenzen, und die gehören benannt. 60 Texte sind eine solide, aber keine riesige Stichprobe; einzelne Prozentpunkte Unterschied sollten nicht überinterpretiert werden. Die KI-Texte stammen aus einem Sprachmodell; andere Modelle können andere Signalmuster ergeben. Das menschliche Korpus deckt enzyklopädische und reisejournalistische Register ab, keine studentischen Hausarbeiten. Die überarbeiteten Texte stammen aus genau einem Tool, unserem eigenen; andere Überarbeitungs-Tools können andere Ergebnisse liefern. Und Detektoren werden laufend aktualisiert, weshalb dieser Benchmark eine Momentaufnahme vom 12. Juni 2026 ist. Wir wiederholen den Test in regelmäßigen Abständen.
Die Ergebnisse
Bevor du die Tabellen liest, eine Einordnung, die für alle drei Tools gilt: Ein Detektor-Score ist ein statistisches Risikosignal, kein Nachweis der Urheberschaft. Kein Wert in diesen Tabellen beweist, dass ein bestimmter Text von einem Menschen oder einer Maschine stammt. Wer Scores für Entscheidungen mit Konsequenzen nutzt, braucht immer Kontext und eine zusätzliche menschliche Prüfung.
Tabelle 1: Kern-Benchmark (menschliche + unveränderte KI-Texte)
Der Kern-Benchmark umfasst die 40 Texte, bei denen die Erkennungsaufgabe klar definiert ist: 20 menschliche Texte (korrekt = niedriges KI-Signal) und 20 unveränderte KI-Texte (korrekt = hohes KI-Signal). Der Stress-Test mit überarbeiteten Texten folgt separat in Tabelle 4.
| Detektor | Korrekte Signale (von 40) | Ergebnis Kern-Benchmark |
|---|---|---|
| Walter Writes | 40 | 40 von 40 |
| GPTZero | 39 | 39 von 40 |
| ZeroGPT | 22 | 22 von 40 |
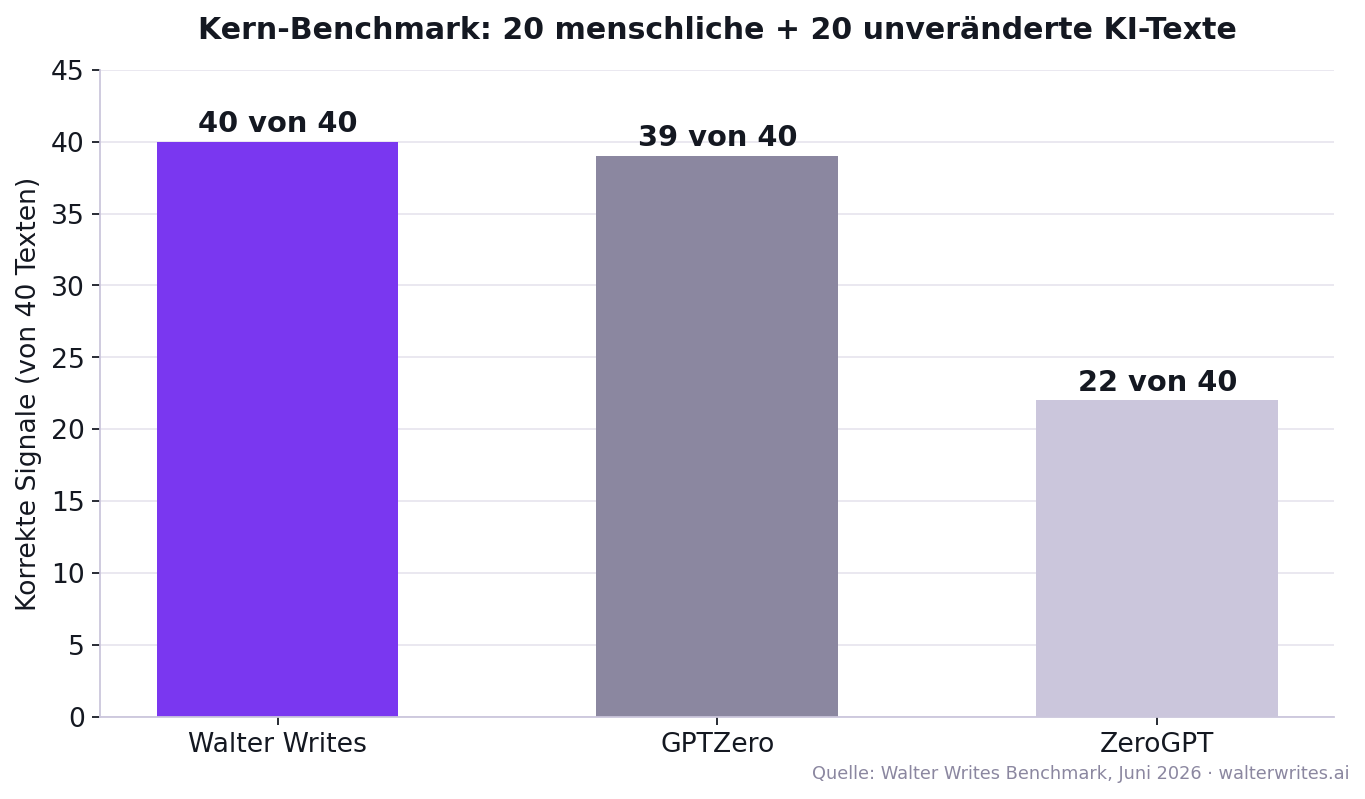
Tabelle 2: False Positives (menschliche Texte mit hohem KI-Signal)
Die wichtigste Tabelle für alle, die Detektoren in Schule oder Hochschule einsetzen. Jeder Wert hier steht für einen echten menschlichen Text, der zu Unrecht verdächtigt worden wäre. Zur Erinnerung: Alle 20 menschlichen Texte stammen nachweislich aus der Zeit vor 2020.
| Detektor | Hohes KI-Signal (von 20) | False-Positive-Rate |
|---|---|---|
| Walter Writes | 0 | 0 % |
| GPTZero | 0 | 0 % |
| ZeroGPT | 7 | 35 % |
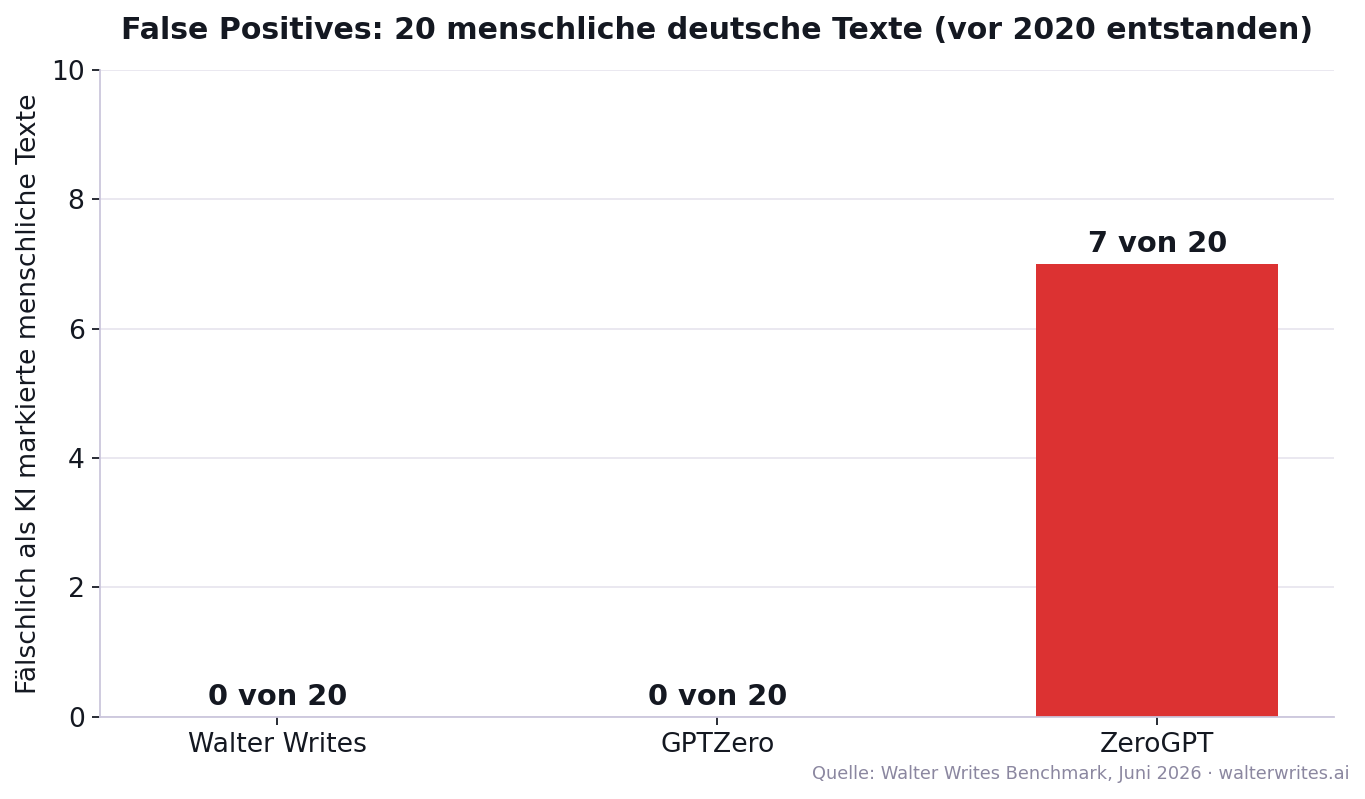
Der Mittelwert der KI-Scores über alle 20 menschlichen Texte macht den Unterschied noch deutlicher: Walter Writes 13,2, GPTZero 0,0, ZeroGPT 34,3. ZeroGPT vergab sein höchstes KI-Signal ausgerechnet an einen Lexikonartikel über Marie Curie (96,6 Prozent), gefolgt von Texten über die Nordsee (90,7 Prozent) und Ludwig van Beethoven (71,8 Prozent). Alle drei sind seit Jahren öffentlich dokumentierte, von Menschen geschriebene Enzyklopädie-Texte.
Tabelle 3: Unveränderte KI-Texte (False Negatives)
Wie viele der 20 unveränderten KI-Texte bekamen ein hohes KI-Signal?
| Detektor | Hohes KI-Signal (von 20) | Übersehen (False Negatives) |
|---|---|---|
| Walter Writes | 20 | 0 |
| GPTZero | 19 | 1 |
| ZeroGPT | 9 | 11 |
Aufschlussreich ist, welche KI-Texte durchrutschten. ZeroGPT erkannte alle 7 Texte aus einfachen Standardprompts, aber nur 2 von 7 Texten mit Stilvorgaben und keinen einzigen der Texte, die mit der Anweisung „klinge locker und menschlich“ erzeugt wurden. Schon eine simple Stilanweisung im Prompt genügte also, um ZeroGPTs Signal zusammenbrechen zu lassen. GPTZero übersah genau einen Text, ebenfalls aus der Kategorie mit Locker-Anweisung (36,1 Prozent). Der Walter Writes KI-Detektor vergab bei allen 20 unveränderten KI-Texten ein hohes Signal, über alle vier Prompt-Typen hinweg.
Tabelle 4: Stress-Test mit überarbeiteten KI-Texten
Der Stress-Test ist bewusst die schwierigste Disziplin und wird deshalb getrennt vom Kern-Benchmark ausgewiesen: Er zeigt, wo Detektion praktisch an Grenzen stößt. Wie viele der 20 zweifach überarbeiteten KI-Texte bekamen trotz Überarbeitung noch ein hohes KI-Signal?
| Detektor | Hohes KI-Signal (von 20) | Signalrate überarbeitet |
|---|---|---|
| Walter Writes | 7 | 35 % |
| GPTZero | 3 | 15 % |
| ZeroGPT | 1 | 5 % |
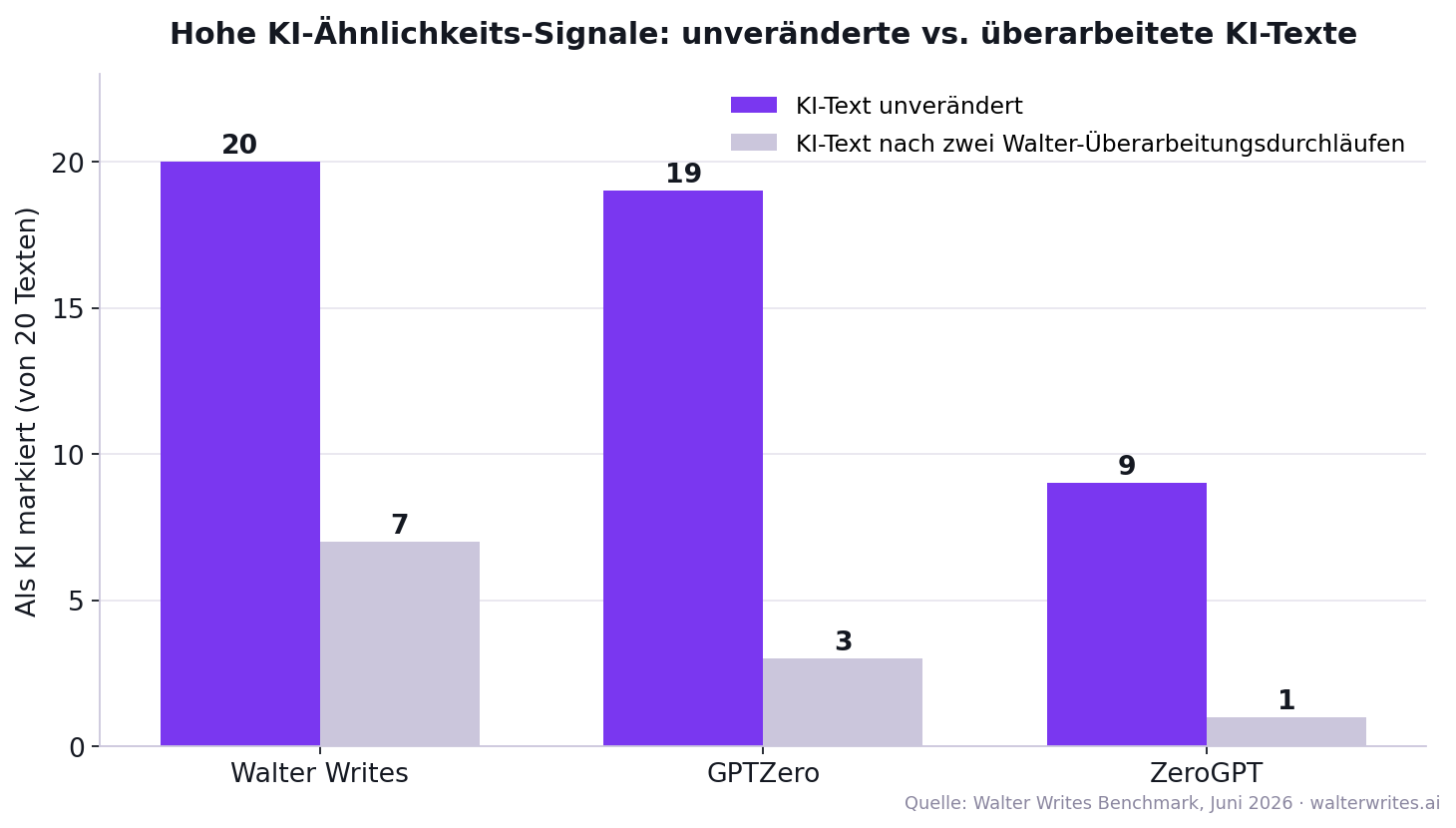
12 der 20 überarbeiteten Texte erhielten bei allen drei Detektoren gleichzeitig ein niedriges KI-Signal. Bemerkenswert dabei: Den höchsten Anteil hoher Signale auf die überarbeiteten Texte vergab der Walter Writes KI-Detektor selbst (7 von 20), also auf Texte aus dem hauseigenen Überarbeitungs-Tool. Wir veröffentlichen diese Zahl bewusst, denn sie zeigt zwei Dinge: Erkennung und Überarbeitung sind zwei getrennte statistische Aufgaben, und kein seriöser Anbieter kann garantieren, dass überarbeitete Texte unsichtbar sind. Wer dir das verspricht, verkauft dir ein Märchen.
Tabelle 5: Gesamtübereinstimmung inklusive Stress-Test
Rechnet man Kern-Benchmark und Stress-Test zusammen: Bei wie vielen der 60 Texte passte das Signal zur bekannten Herkunft?
| Detektor | Signal passt zur Herkunft (von 60) | Gesamtübereinstimmung inkl. Stress-Test |
|---|---|---|
| Walter Writes | 47 | 78,3 % |
| GPTZero | 42 | 70,0 % |
| ZeroGPT | 23 | 38,3 % |
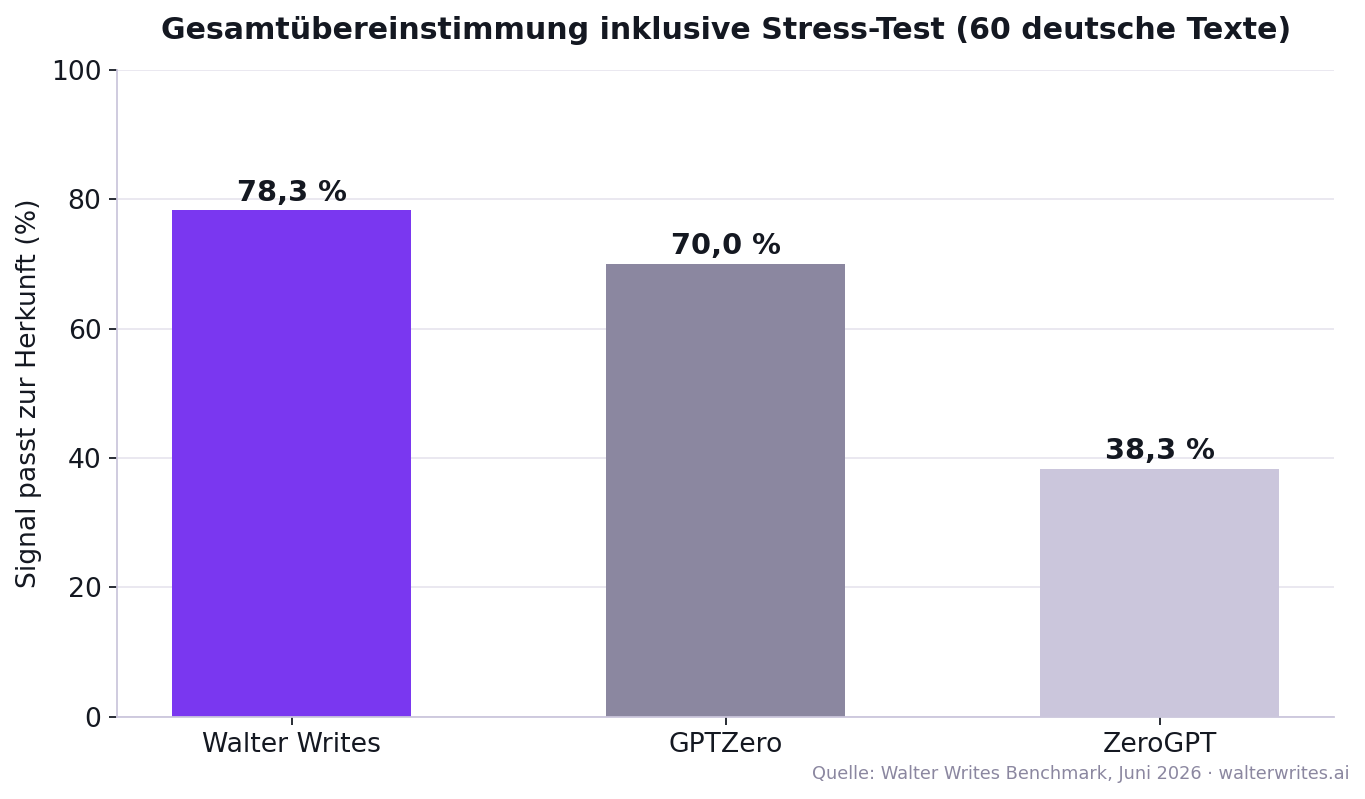
Diese Gesamtzahl beschreibt keine allgemeine Produktgenauigkeit. Sie verrechnet den klar definierten Kern-Benchmark mit dem bewusst schwierigen Stress-Test und fällt deshalb bei allen Tools niedriger aus als die Kern-Benchmark-Quote.
So sollte man den Benchmark lesen: Walter Writes zeigte in diesem Testfeld das stärkste Profil für deutsche Workflows: keine False Positives bei menschlichen Texten, 20 von 20 hohe Signale bei unveränderten KI-Texten und die höchste Gesamtübereinstimmung inklusive Stress-Test. Gleichzeitig zeigt der Test klar, dass kein KI-Detektor Urheberschaft beweisen kann. Besonders bei überarbeiteten Texten braucht es menschliche Prüfung, Prozessnachweise und Kontext.
Was die Ergebnisse bedeuten
Der Abstand zwischen Werbeversprechen und deutscher Realität
Detektor-Anbieter werben üblicherweise mit Genauigkeiten von 98 oder 99 Prozent, gemessen auf englischen Korpora. Unser deutscher Testlauf zeichnet ein differenzierteres Bild. Im Kern-Benchmark aus menschlichen und unveränderten KI-Texten erreichte Walter Writes 40 von 40 korrekten Signalen und GPTZero 39 von 40, ZeroGPT dagegen nur 22 von 40. Wird der schwierige Stress-Test mit überarbeiteten KI-Texten in die Gesamtwertung eingerechnet, lag der beste Wert bei 78,3 Prozent, der schwächste bei 38,3 Prozent. Zwischen den drei getesteten Tools lagen auf Deutsch deutliche Unterschiede. Wer einen Detektor für deutsche Texte auswählt, sollte sich darum nicht auf Genauigkeitsangaben verlassen, die mit englischem Material gemessen wurden, sondern nach deutschsprachigen Testdaten fragen.
False Positives: das eigentliche Risiko
Hier trennt sich das Feld am deutlichsten. Zwei der drei Tools (Walter Writes und GPTZero) markierten keinen einzigen menschlichen deutschen Text fälschlich. ZeroGPT markierte 7 von 20, und zwar bevorzugt formelle, gleichmäßig geschriebene Sachtexte, exakt das Register, in dem auch Hausarbeiten, Abschlussarbeiten und behördliche Texte geschrieben werden. Für den Einsatz an Schulen und Hochschulen wäre eine solche False-Positive-Rate problematisch, weil dort Fairness und Nachvollziehbarkeit wichtiger sind als ein aggressives KI-Signal. Ein Verfahren, das in einem Testfeld jeden dritten menschlichen Text verdächtigt, wäre für Schule und Hochschule schwer verantwortbar.
Überarbeitete Texte: wo die Detektion endet
Zwischen unveränderten und zweifach überarbeiteten KI-Texten brachen die Signalraten bei allen drei Tools deutlich ein: von 20 auf 7 (Walter Writes), von 19 auf 3 (GPTZero) und von 9 auf 1 (ZeroGPT). Für Prüfungsämter ist das die zentrale Zahl, denn sie zeigt, was ein unauffälliger Detektor-Befund tatsächlich wert ist: wenig. Ein niedriges KI-Signal bedeutet nicht, dass ein Text von einem Menschen stammt; es bedeutet nur, dass der Text keine auffälligen statistischen Muster mehr trägt. Wer auf dieser Grundlage Freisprüche oder Verurteilungen ausspricht, überfordert die Technologie in beide Richtungen.
Die Mittelwerte erzählen dieselbe Geschichte differenzierter: Bei den überarbeiteten Texten lag der mittlere Walter-Score bei 49,3, also genau im Graubereich der Skala, während GPTZero im Mittel auf 30,2 und ZeroGPT auf 10,7 fiel. Ein Score nahe der Mitte ist die ehrlichste Antwort, die ein statistisches System geben kann: unsicher. Genau so sollten solche Werte auch gelesen werden, als Anlass für eine genauere Prüfung, nicht als Urteil.
Wenn drei Tools dreimal anders werten
Bei 25 der 60 Texte kamen die drei Detektoren nicht zum selben Ergebnis. Das ist kein Skandal, sondern eine Eigenschaft statistischer Systeme mit unterschiedlichen Trainingsdaten und Schwellenwerten. Praktisch folgt daraus eine einfache Regel: Verlasse dich nie auf einen einzelnen Score. Wenn zwei Tools denselben Text gegensätzlich bewerten, sagt das mehr über die Messunsicherheit als über den Text. Nutze mehrere Signale, lies den Text selbst und sprich im Zweifel mit der Person, die ihn geschrieben hat.
Einordnung für Lehrkräfte und Unis
Wenn du als Lehrkraft, Dozentin oder Prüfungsverantwortlicher mit Detektor-Scores arbeitest, ist die wichtigste Erkenntnis aus diesem Test unabhängig von den konkreten Zahlen: Ein Score ist ein Hinweis, kein Beweis.
Kein Detektor in diesem Test arbeitet fehlerfrei, und keiner wird es in absehbarer Zeit tun. Die Tools messen statistische Wahrscheinlichkeiten, keine Urheberschaft. Ein Detektor kann nicht wissen, wer einen Text geschrieben hat. Er kann nur sagen, dass ein Text Muster enthält, die in seinen Trainingsdaten häufiger bei maschinell erzeugten Texten vorkamen. Bei deutschen Texten kommt die zusätzliche Unsicherheit durch englisch-lastige Trainingsdaten dazu.
Daraus folgen vier Empfehlungen für den fairen Einsatz:
- Nutze Detektoren als Anlass für ein Gespräch, nicht als Urteil. Ein hohes Signal rechtfertigt eine Nachfrage zum Entstehungsprozess, etwa ein kurzes Gespräch über Gliederung, Quellen und Argumentation. Es rechtfertigt keine Sanktion.
- Verlange nie, dass Studierende ihre Unschuld gegen einen Score beweisen. Die Beweislast umzukehren ist bei einer Technologie mit dokumentierten False Positives nicht haltbar, weder didaktisch noch rechtlich.
- Prüfe mit mehreren Tools und achte auf Widersprüche. In unserem Testlauf bewerteten die drei Detektoren 25 von 60 Texten unterschiedlich. Widersprüche zwischen Tools sind ein Signal, die Unsicherheit ernst zu nehmen.
- Setze auf Prozessnachweise statt auf Endprodukt-Forensik. Versionsverläufe, Zwischenstände und mündliche Verteidigungen sind belastbarer als jeder Score. Einige Hochschulen verankern das bereits in ihren Prüfungsordnungen.
Wer tiefer einsteigen will, findet in unserem Leitfaden zum Thema KI-Texte erkennen eine ausführliche Darstellung, woran man maschinell erzeugte Texte erkennen kann und wo die Grenzen dieser Methoden liegen. Unseren Einzeltest zu GPTZero mit deutschen Texten liest du unter GPTZero auf Deutsch.
Was dieser Test zeigt und was nicht
Was dieser Test zeigt: Erstens, die Sprachfrage ist real: Tools, die auf Englisch ähnlich beworben werden, liegen auf Deutsch im Kern-Benchmark 18 von 40 Signalen auseinander. Zweitens, für deutsche Texte gab es im Testfeld einen klaren praktischen Unterschied: Der Walter Writes KI-Detektor zeigte das stärkste Profil, 40 von 40 korrekte Signale im Kern-Benchmark aus menschlichen und unveränderten KI-Texten, null False Positives und die höchste Gesamtübereinstimmung inklusive Stress-Test. Für deutschsprachige Workflows zeigte Walter in diesem Testfeld damit das stärkste praktische Profil. GPTZero ist ein nützliches Tool mit sehr sauberem Verhalten bei unveränderten Texten, aber englisch-zentriert aufgebaut; das nimmt einem deutschen Workflow nicht den praktischen Vorteil einer Lösung, die deutschsprachige Erkennung, Überarbeitung und menschliche Prüfung an einem Ort verbindet. Drittens, ZeroGPT zeigte in diesem deutschen Testfeld deutliche Schwächen in beide Richtungen.
Was dieser Test nicht zeigt: Er beweist nicht, dass irgendein Detektor einzelne Texte fehlerfrei beurteilt, auch unserer nicht. Er sagt nichts über englische Texte, nichts über andere Sprachmodelle als das verwendete und nichts über künftige Tool-Versionen. Und er zeigt ausdrücklich nicht, dass überarbeitete KI-Texte „sicher“ wären: 12 von 20 passierten alle drei Tools, aber Detektoren sind nur eine von mehreren Prüfebenen, und maschinelle Überarbeitung ohne menschliche Schlussredaktion bleibt erkennbar fehleranfällig.
Unsere Position
KI-Detektion ist ein praktisches Schreibsignal, kein gerichtsfester Beweis. Wir entwickeln selbst einen Detektor und einen Humanizer, und gerade deshalb sagen wir es so deutlich: Der sicherste Arbeitsablauf ist Erkennung, Überarbeitung, menschliche Prüfung und eine abschließende Kontrolle, nicht blindes Vertrauen in einen einzelnen Score.
Das Ziel ist verantwortungsvolles KI-gestütztes Schreiben: Texte, die inhaltlich stimmen, natürlich klingen und vor Abgabe oder Veröffentlichung von einem Menschen geprüft wurden. Genau für diesen Arbeitsablauf ist Walter gebaut, mit deutschsprachiger Erkennung, Überarbeitung und Prüfung an einem Ort. Du kannst den KI-Detektor kostenlos nutzen, und in unserem Überblick der besten KI-Detektor-Tools findest du Kurzporträts weiterer Anbieter.
Methodik-Transparenz und Daten zum Download
Vertrauen entsteht durch Nachprüfbarkeit. Deshalb stellen wir das komplette Material dieser Studie offen zur Verfügung:
- Rohdaten: alle 180 Einzelmessungen als CSV, inklusive Scores, Klassifikationen und Zeitstempeln. (CSV herunterladen)
- Aggregierte Kennzahlen: alle berechneten Metriken als JSON. (JSON-Kennzahlen herunterladen)
- Korpus-Dokumentation: die Promptliste der KI-Texte, die vollständigen KI- und überarbeiteten Texte sowie die Quellenliste der menschlichen Texte mit Wikipedia-Revisions-IDs (die menschlichen Texte verlinken wir als Quellenangaben, statt sie zu kopieren). (Korpus-Paket herunterladen)
Wenn du Fehler in der Methodik findest oder Ergebnisse nicht reproduzieren kannst, schreib uns. Korrekturen werden in diesem Artikel transparent vermerkt. Der Test wird in regelmäßigen Abständen mit aktualisierten Tool-Versionen wiederholt; die jeweils aktuelle Fassung findest du immer unter dieser URL.
Häufige Fragen
Welcher KI-Detektor ist der beste für deutsche Texte?
In unserem Benchmark mit 60 deutschen Texten (Juni 2026) zeigte der Walter Writes KI-Detektor das stärkste Profil: 40 von 40 korrekte Signale im Kern-Benchmark aus menschlichen und unveränderten KI-Texten, null fälschlich markierte menschliche Texte und die höchste Gesamtübereinstimmung inklusive Stress-Test (47 von 60). GPTZero folgte mit 39 von 40 im Kern-Benchmark, ebenfalls ohne False Positives. Wichtiger als der Spitzenwert ist das Profil: Für Schule und Hochschule zählt vor allem eine niedrige False-Positive-Rate, für Redaktionen das Verhalten bei überarbeiteten Texten. Die Details stehen in den fünf Ergebnistabellen weiter oben.
Warum liegt die höchste Gesamtübereinstimmung nur bei 78,3 Prozent?
Weil die Gesamtwertung auch einen bewusst schwierigen Stress-Test enthält: 20 KI-Texte, die nach der Generierung zweimal maschinell überarbeitet wurden. Diese Texte sollen zeigen, wo Detektion praktisch an Grenzen stößt. Im Kern-Benchmark aus 20 menschlichen und 20 unveränderten KI-Texten erreichte Walter Writes 40 von 40 korrekte Signale. Die 78,3 Prozent beschreiben also nicht eine allgemeine Produktgenauigkeit, sondern die Gesamtübereinstimmung in diesem bewusst anspruchsvollen Testfeld.
Wie vertrauenswürdig sind KI-Detektoren?
Sie liefern brauchbare Risikosignale, aber keine Beweise. In unserem Test markierte das schwächste Tool 7 von 20 menschlich geschriebenen deutschen Texten fälschlich als KI, und zweifach überarbeitete KI-Texte erhielten im Schnitt nur noch bei 18 Prozent der Messungen ein hohes Signal. Ein Detektor-Score sollte darum immer als Hinweis behandelt werden, der weitere Prüfung auslöst, nie als alleinige Entscheidungsgrundlage.
Warum bewerten verschiedene Detektoren denselben deutschen Text unterschiedlich?
Weil jedes Tool andere Trainingsdaten, Modelle und Schwellenwerte nutzt und die meisten überwiegend auf Englisch trainiert sind. Deutsche Texte haben andere statistische Eigenschaften: längere Komposita, flexiblere Satzstellung, eine andere Verteilung von Satzlängen und Funktionswörtern. In unserem Testlauf bewerteten die drei Tools 25 von 60 Texten unterschiedlich. Solche Widersprüche sind ein Grund, mehrere Signale zu kombinieren und die Texte selbst zu lesen, nicht ein Grund, einem einzelnen Tool blind zu vertrauen.
Wie oft werden menschliche Texte fälschlich als KI markiert?
In unserem Test lag die False-Positive-Rate je nach Tool zwischen 0 und 35 Prozent (Tabelle 2). Auf eine Hochschule mit tausenden eingereichten Arbeiten pro Semester hochgerechnet bedeutet selbst eine niedrige Rate hunderte zu Unrecht verdächtigte Texte pro Jahr. Genau deshalb darf ein einzelner Score nie automatisch zu einer Konsequenz führen.
Sagt Walter, dass GPTZero oder ZeroGPT schlechte Tools sind?
Nein. GPTZero hat in diesem Test bei unveränderten Texten sehr sauber gearbeitet, null False Positives und nur ein übersehener KI-Text, und bleibt ein nützliches Werkzeug, vor allem für englische Texte. ZeroGPT zeigte in dieser Messung auf Deutsch deutliche Schwächen in beide Richtungen; das kann sich mit künftigen Versionen ändern. Unser Punkt ist ein anderer: Walter zeigte in diesem Testfeld das stärkste praktische Profil für deutschsprachige Workflows, weil Erkennung, Überarbeitung und menschliche Prüfung in einem Arbeitsablauf zusammenkommen. Und jedes Detektor-Signal braucht menschliche Einordnung.
Beweist ein niedriges KI-Signal, dass ein Text von einem Menschen stammt?
Nein. Kein Detektor kann Urheberschaft beweisen, in keine Richtung. In unserem Test erhielten 12 von 20 zweifach überarbeiteten KI-Texten bei allen drei Tools ein niedriges Signal. Ein niedriger Score heißt nur, dass der Text wenige auffällige statistische Muster trägt. Belastbarer sind Prozessnachweise wie Versionsverläufe und Gespräche über den Entstehungsprozess.
Warum vergibt der Walter Writes KI-Detektor auch auf überarbeitete Walter-Texte teils hohe Signale?
Weil Erkennung und Überarbeitung zwei getrennte statistische Aufgaben sind und wir den Detektor nicht künstlich auf die Ausgaben des eigenen Humanizers „blind“ schalten. 7 von 20 zweifach überarbeiteten Texten bekamen vom Walter Writes KI-Detektor weiterhin ein hohes KI-Ähnlichkeits-Signal. Das ist gewollt transparent: Scores sind Risikosignale, und der empfohlene Arbeitsablauf endet nie beim Tool, sondern bei der menschlichen Prüfung. Der sicherste Arbeitsablauf ist Erkennung, Überarbeitung, menschliche Prüfung und eine abschließende Kontrolle, nicht blindes Vertrauen in einen einzelnen Score.